NLP pour les sciences sociales
Fini les méthodes du passé !
08/02/2024
Introduction
Objectif : Présenter un panorama des méthodes NLP
Natural Language Processing / Traitement Automatique du Langage :
Traiter des données textuelles massives
Assisté par ordinateur : logiciels dédiés, langages informatiques (R, Python)
Pour répondre à une problématique de recherche spécifique
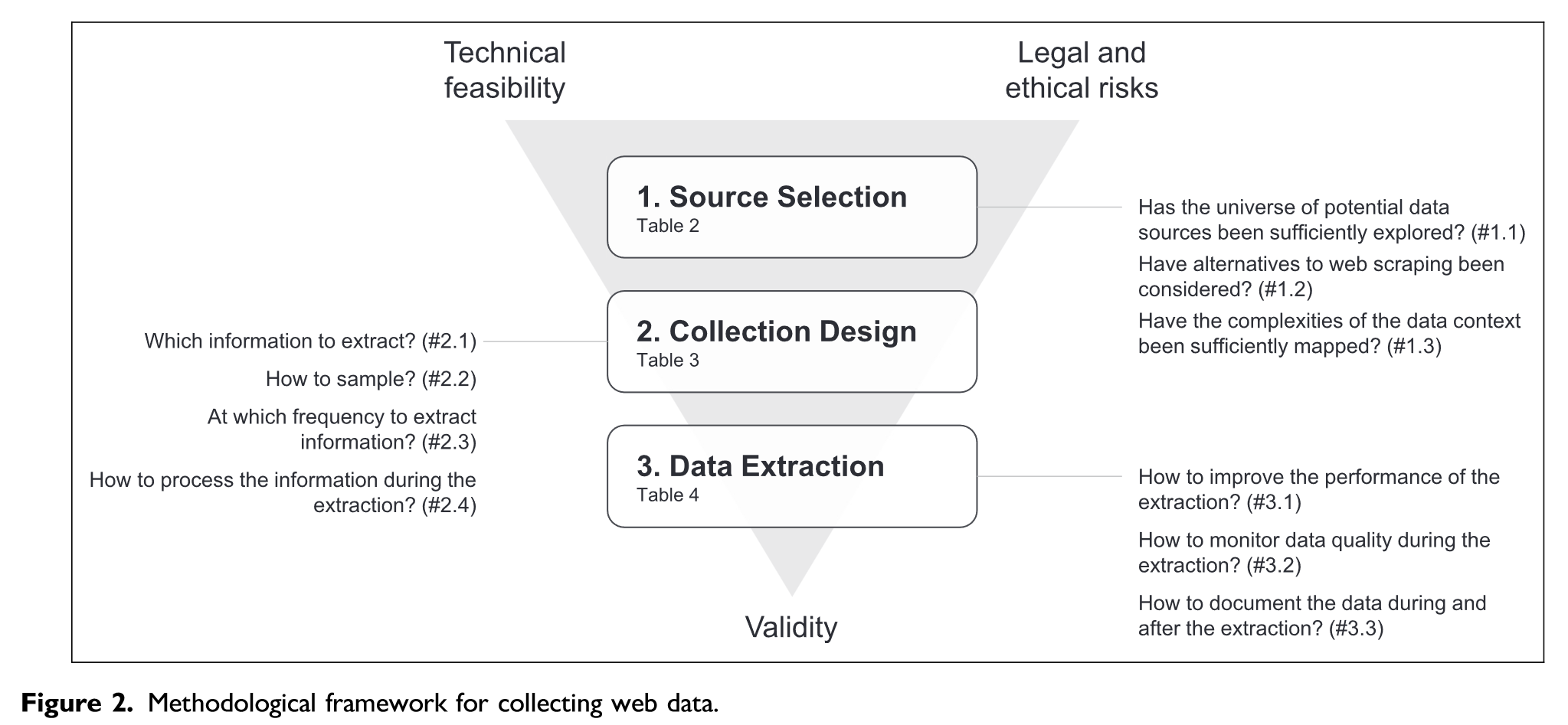
Quelles sources de données ?
Quelles applications ?
Quelles méthodes d’analyse ?
Quelles difficultés ?
1. Quelles sources de données ?
1. Quelles sources de données ?
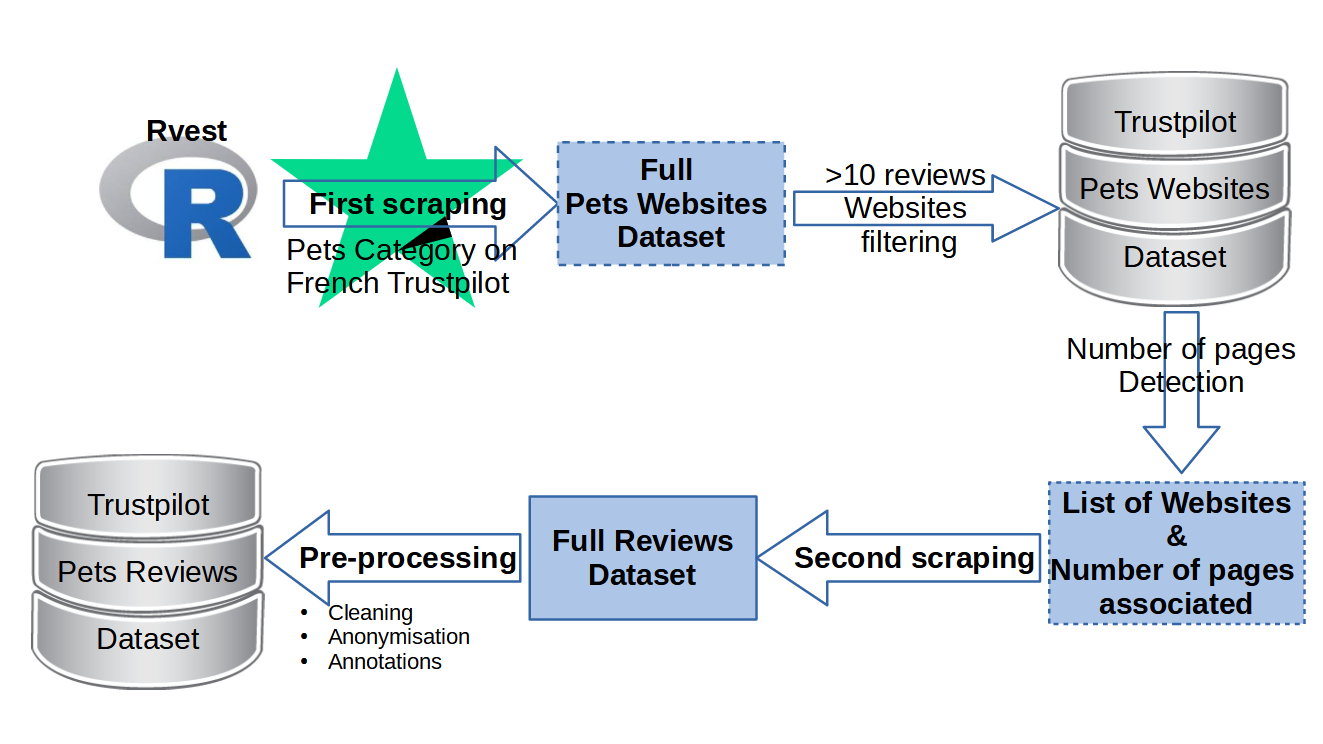
341 613 avis clients concernant 220 sites web
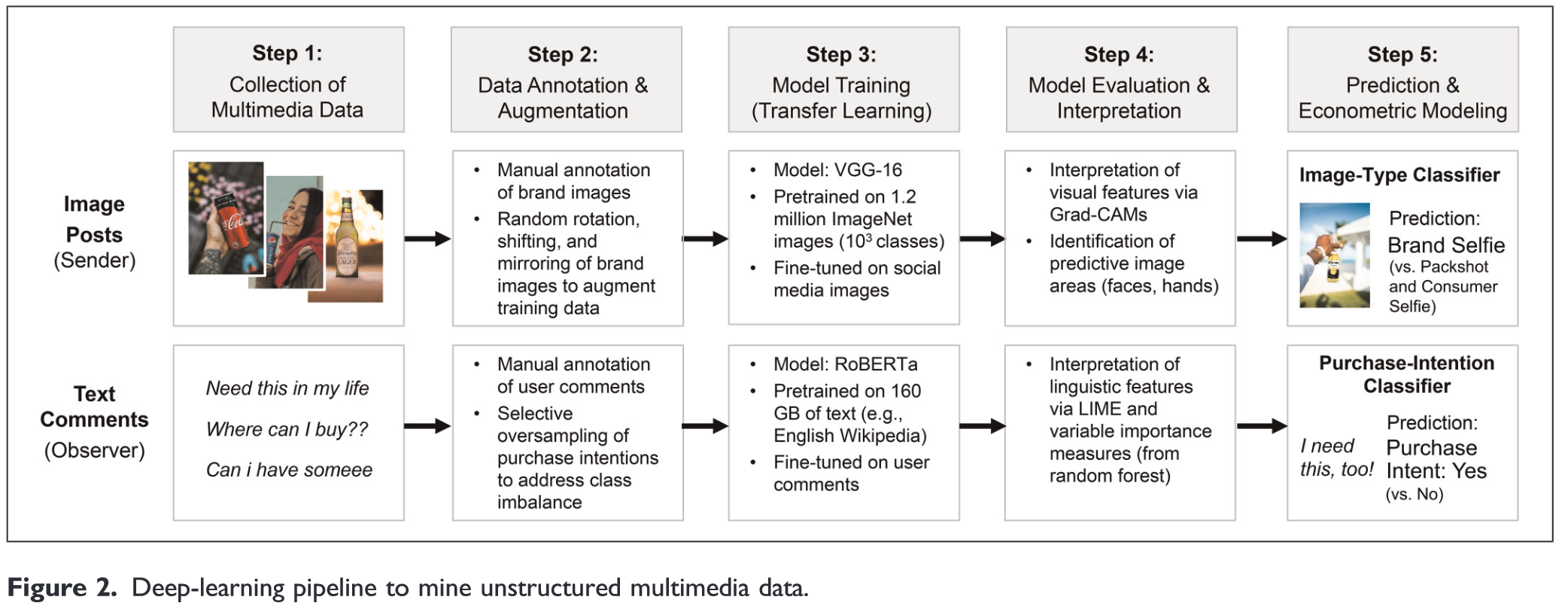
2. Quelles applications ?
Revue de littérature systématique
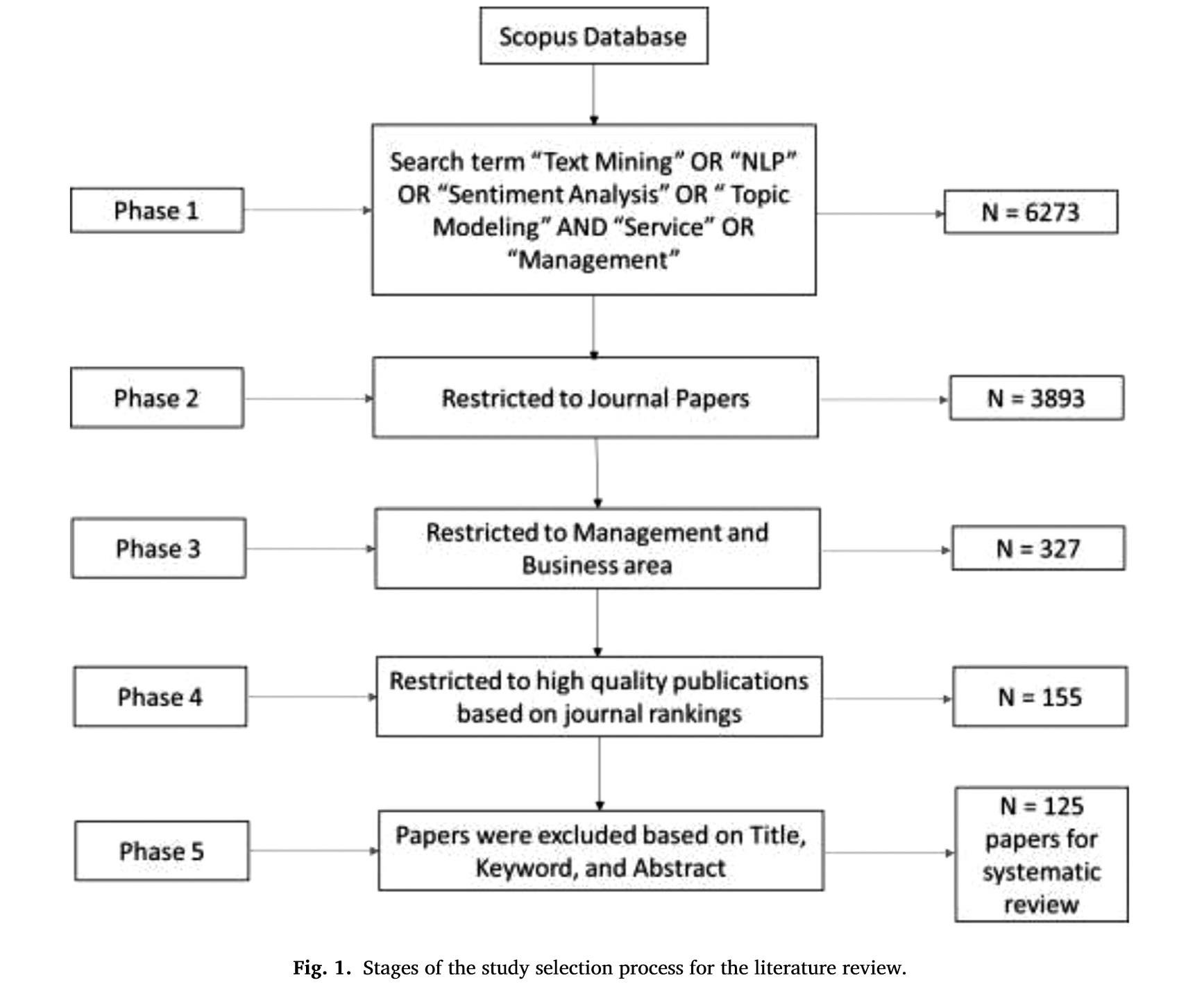

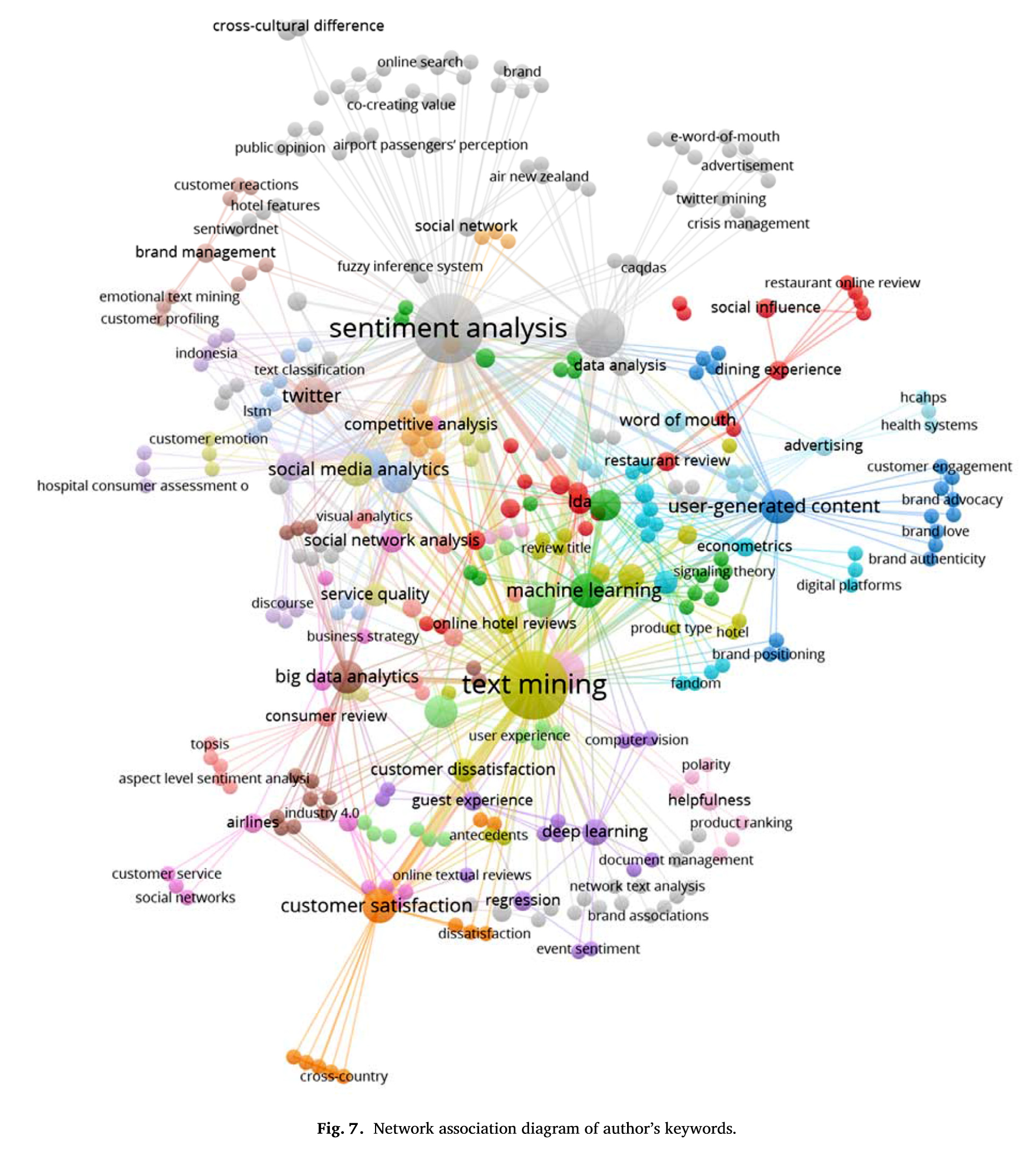
2. Quelles applications ?
Études qualitatives
![]()
![]()
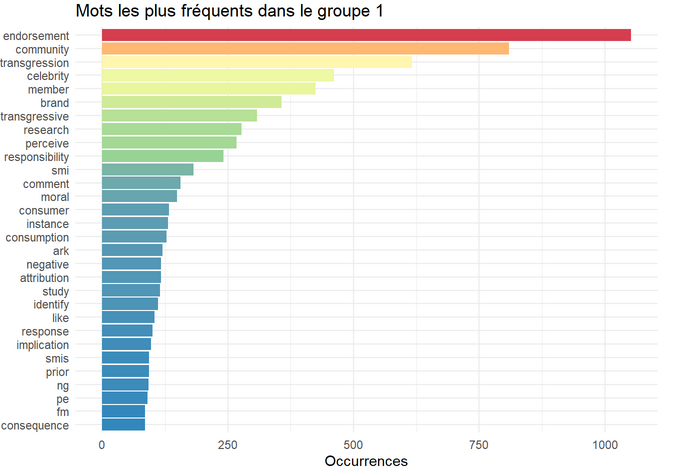
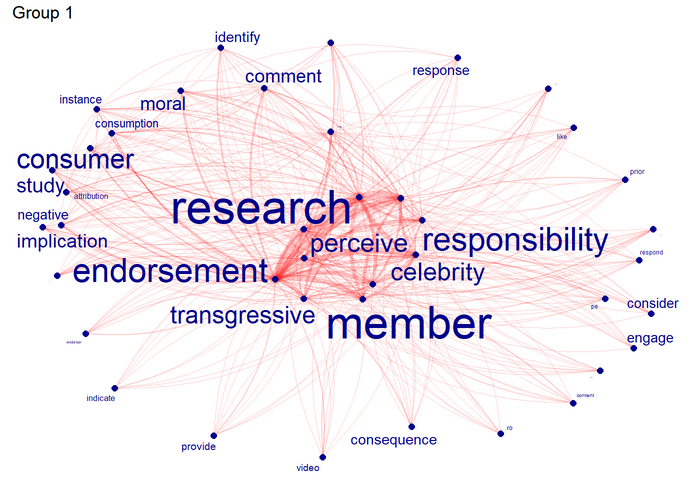
2. Quelles applications ?
Études quantitatives

2. Quelles applications ?
Études quantitatives
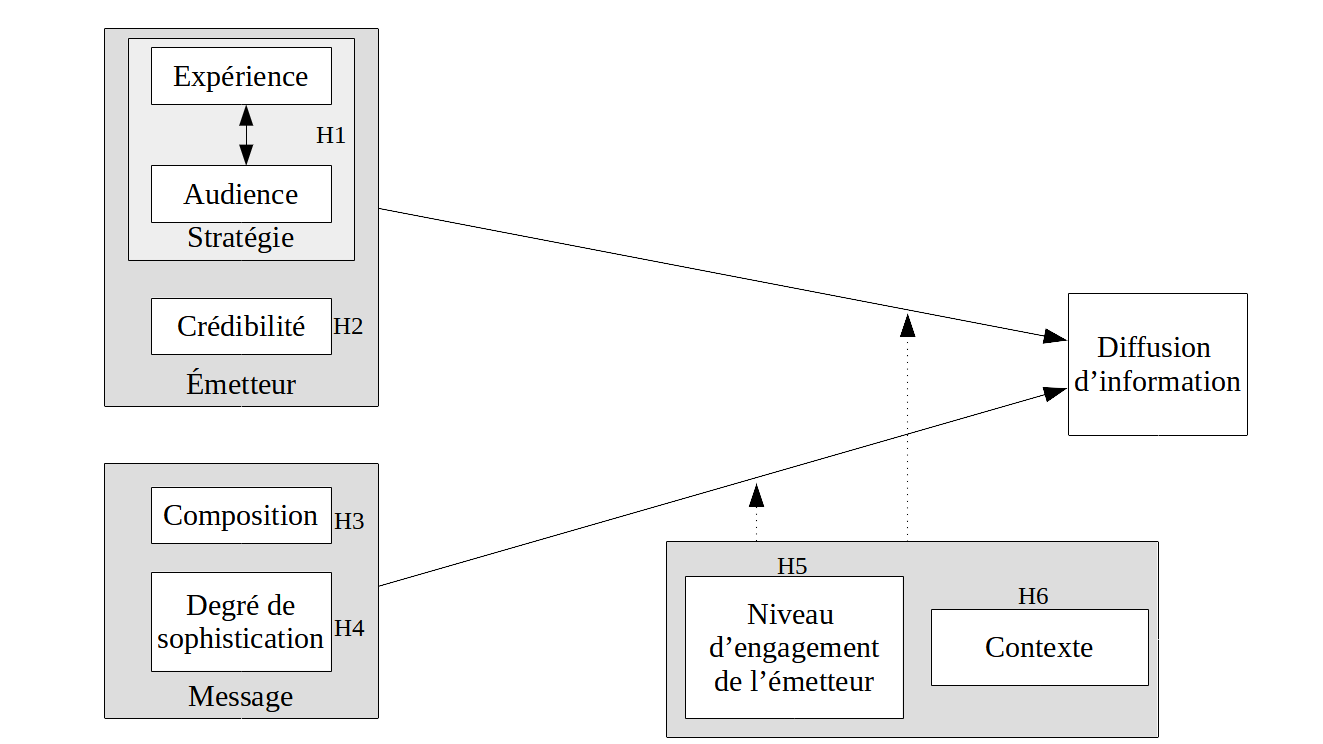
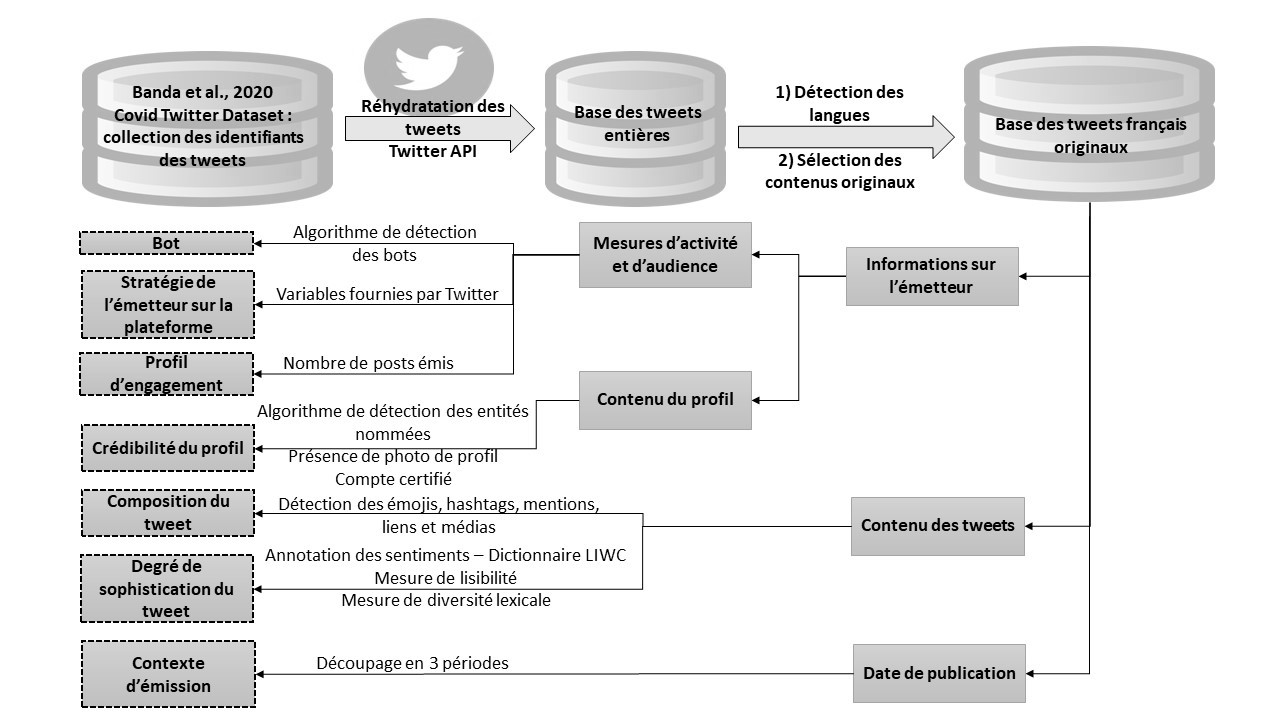
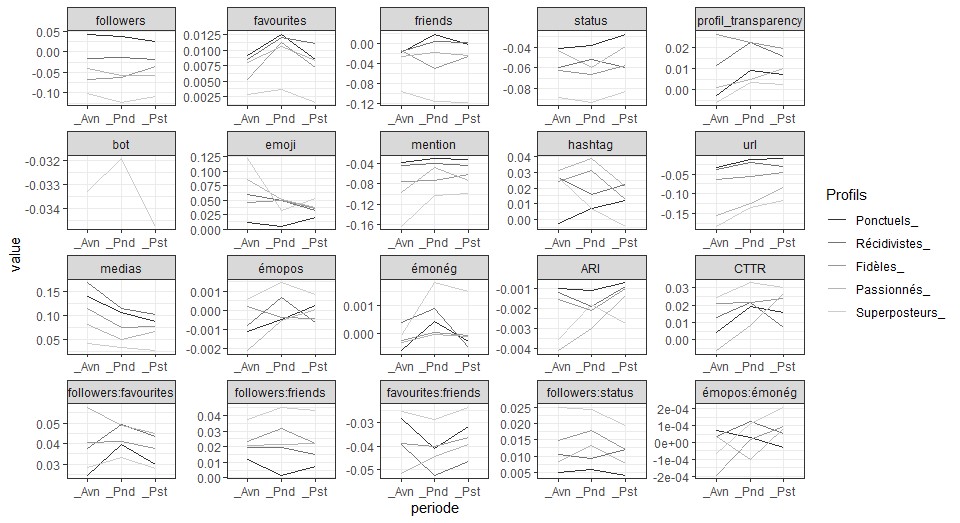
3. Quelles méthodes d’analyse ?
QR : technological innovation increases the number of economic
conditional clauses
Corpus : the whole U.S. state legislation from 1964 to 2000

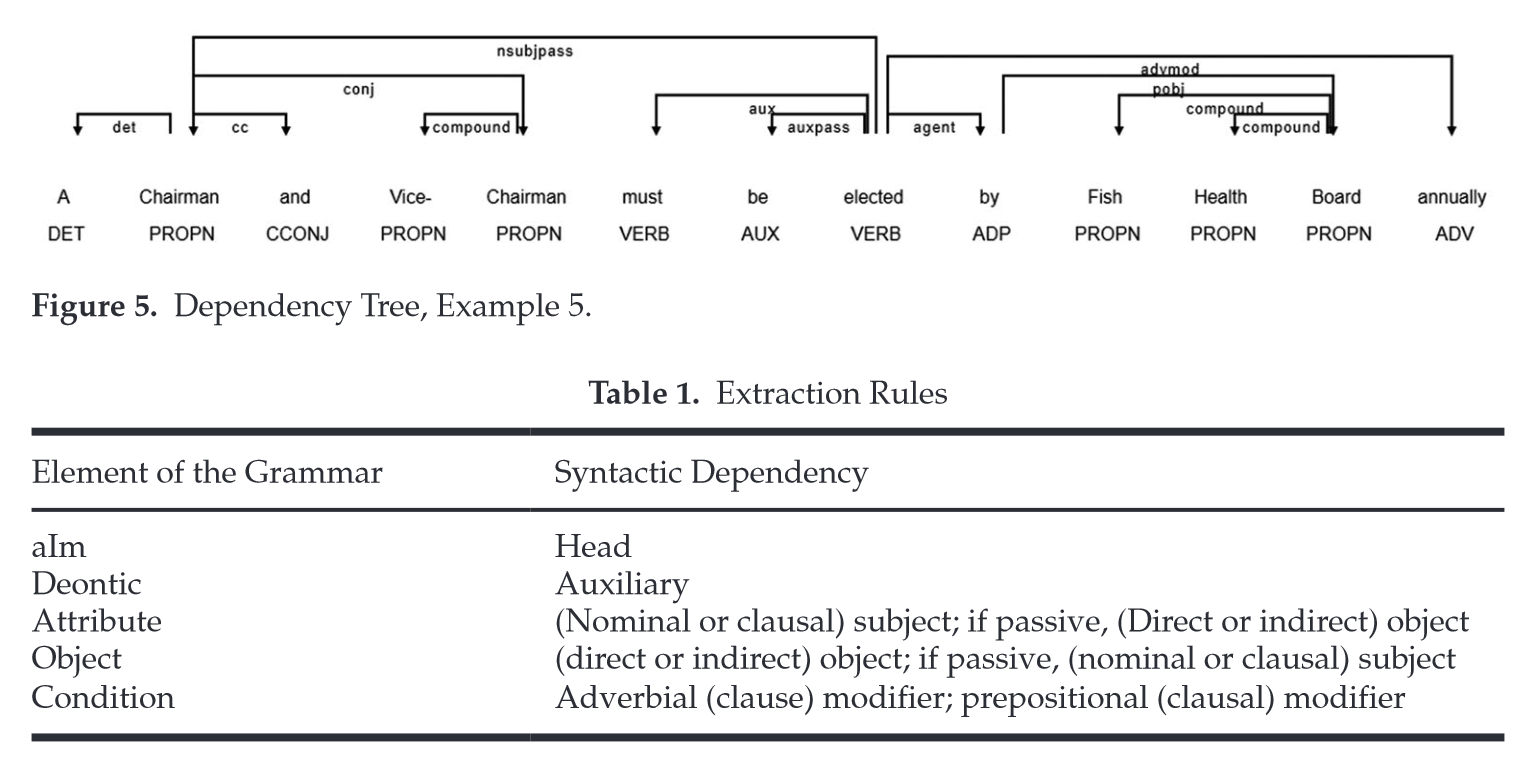
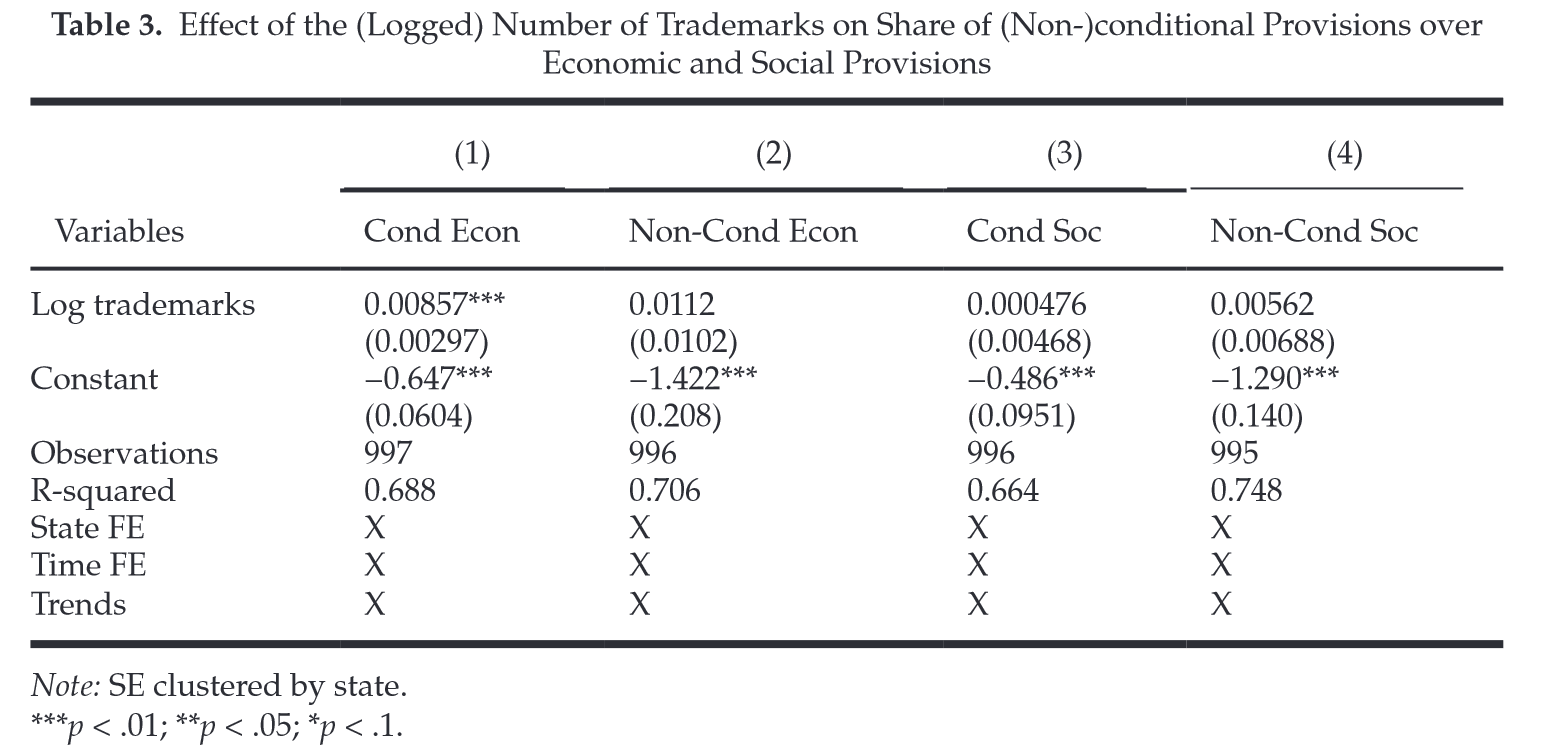
3. Quelles méthodes d’analyse ?
QR : quelle est la contribution des attributs clés de l’expérience
hôtelière à la satisfaction ?
Corpus : 24 301 commentaires de Trip Advisor sur 52 hôtels

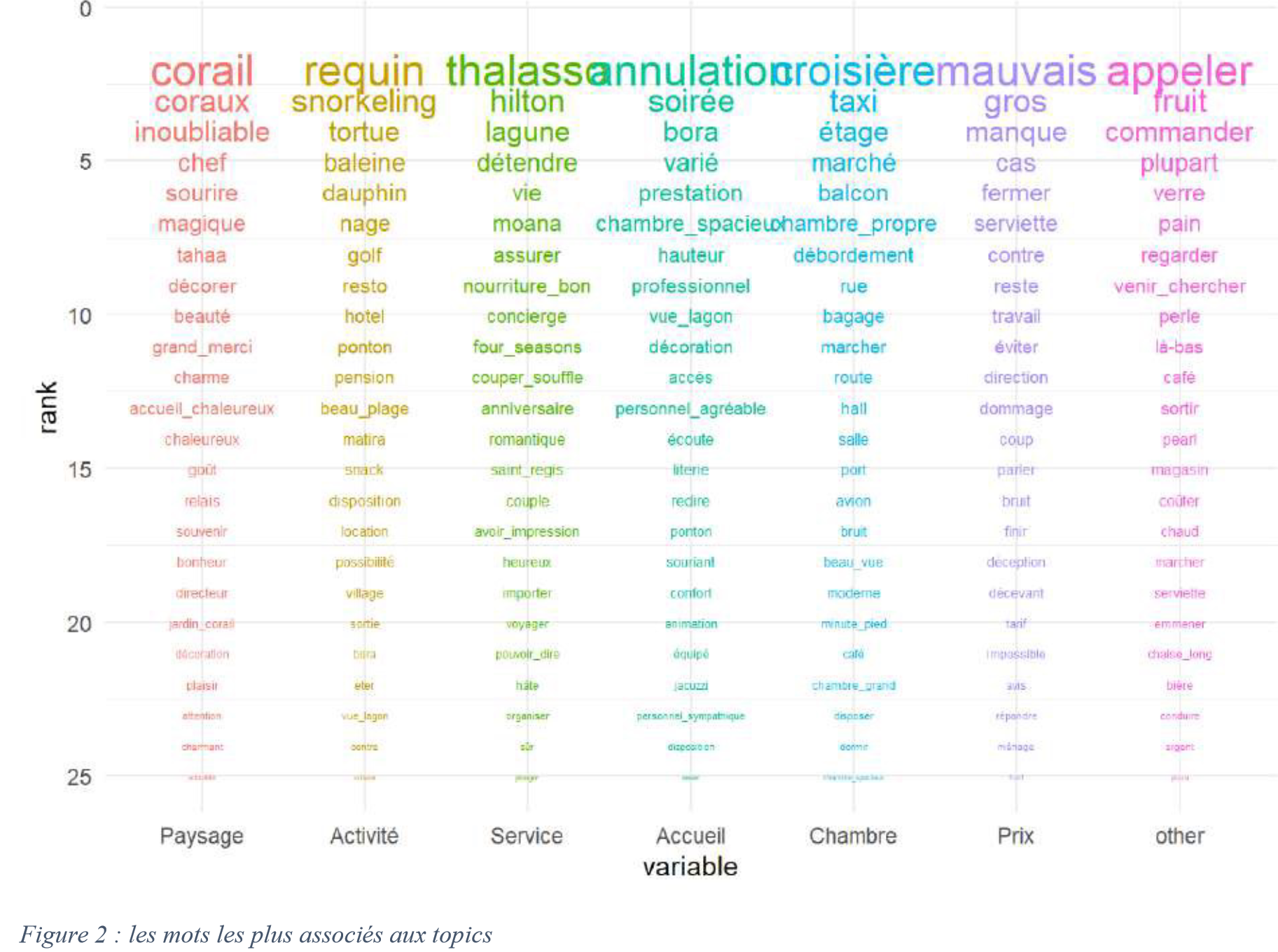

3. Quelles méthodes d’analyse ?
QR : how patterns of speaking are created, picked up, and
ignored or propagated
Corpus : 44,913 speeches from the Archives Parlementaires
of the French Revolution Digital Archive
from 1787 to 1794



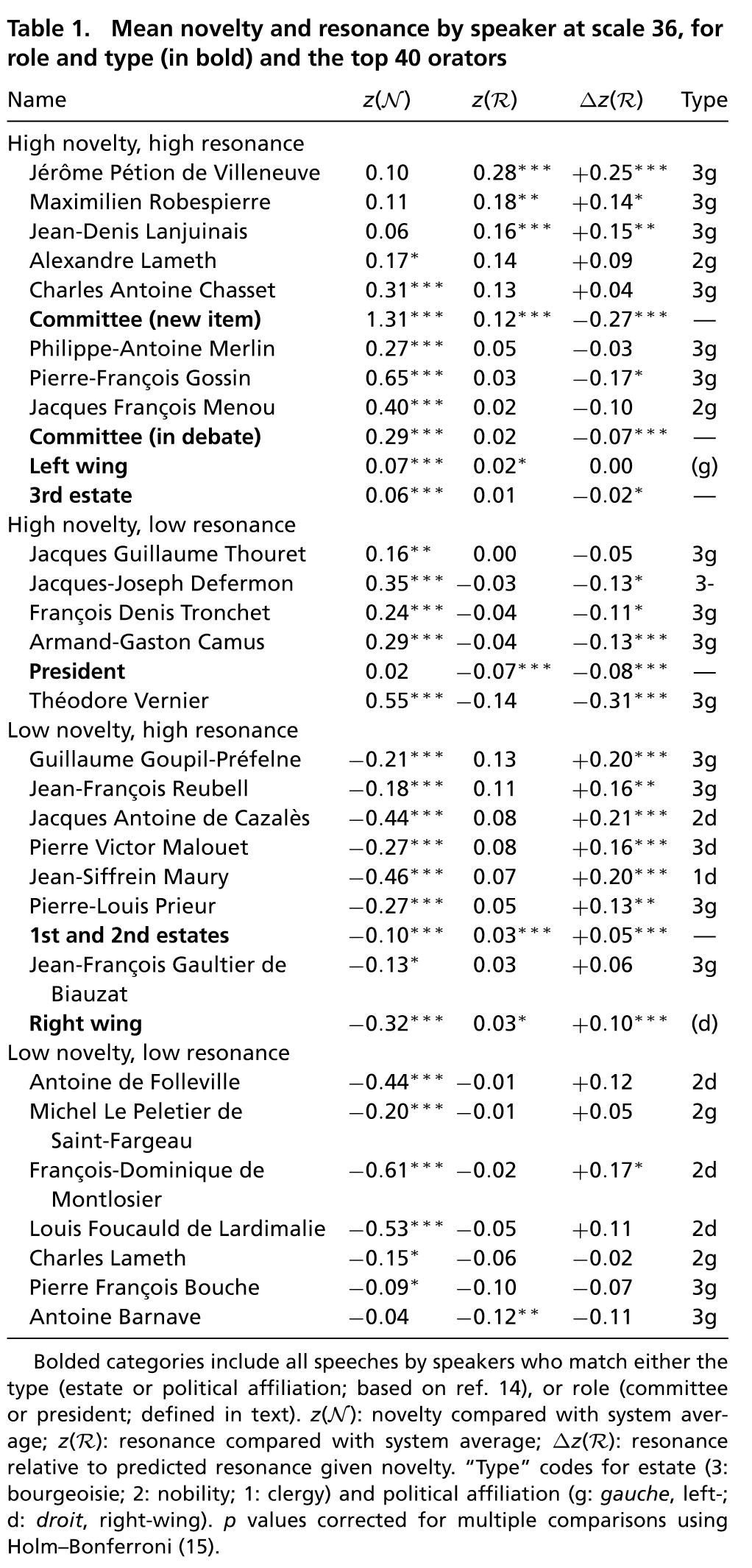
3. Quelles méthodes d’analyse ?
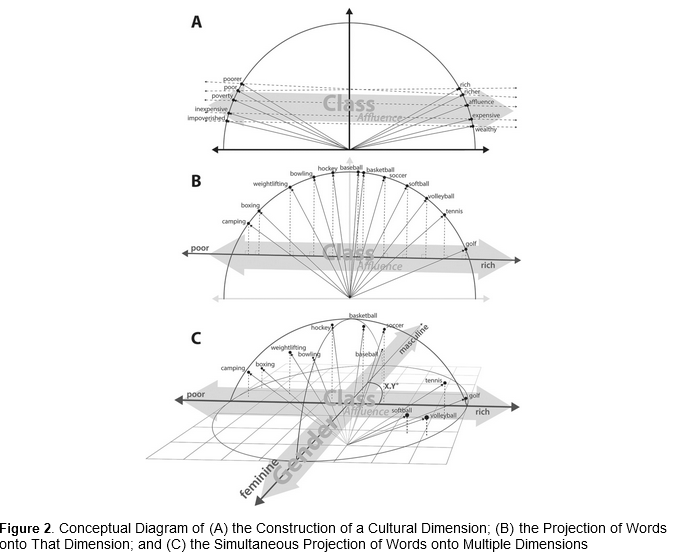
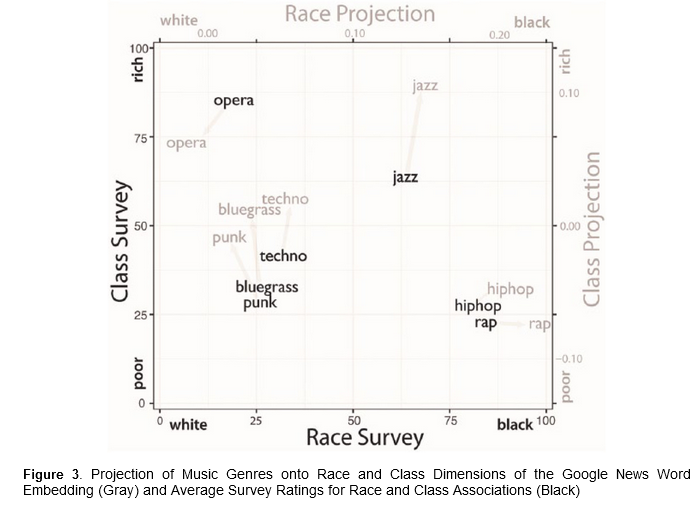
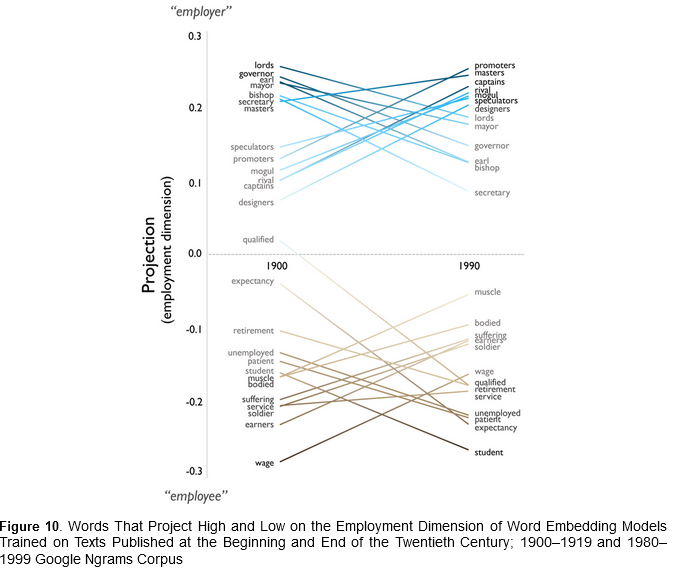
QR : analyze the cultural dimensions of social class and their evolution
over the twentieth century
Corpus : survey of cultural associations to a total of 398 respondents
on Amazon Mechanical Turk + a similar dataset collected in the 1950’s
Google Ngram texts from 1900 to 2012 : collection of 5-grams

3. Quelles méthodes d’analyse ?
QR : investigate the predictive power of the inferred personality
for their future reviews
Corpus : Yelp Academic Dataset focused on the “restaurant” category
160,578 reviews written by 74,480 reviewers for 4,244 restaurants

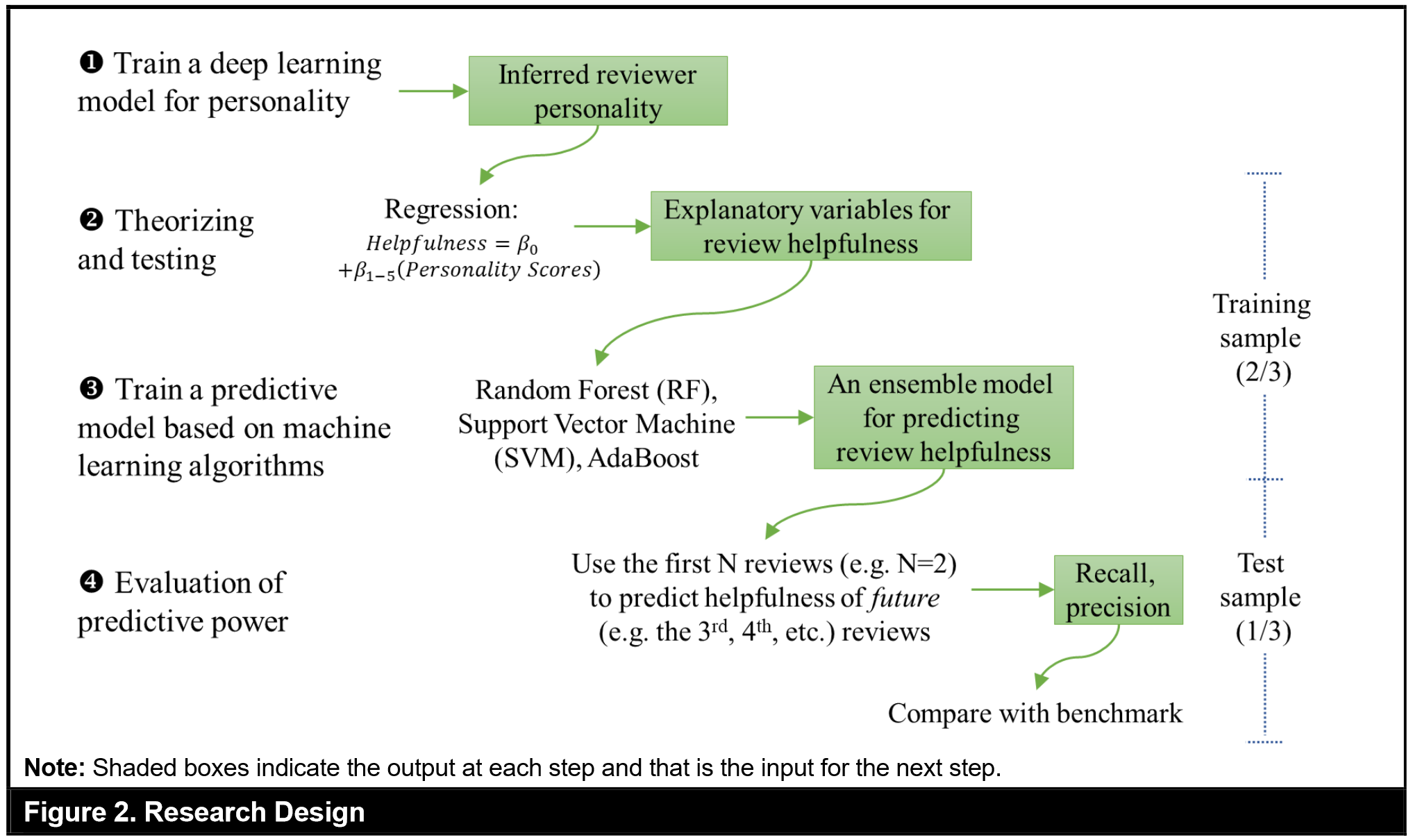
3. Quelles méthodes d’analyse ?
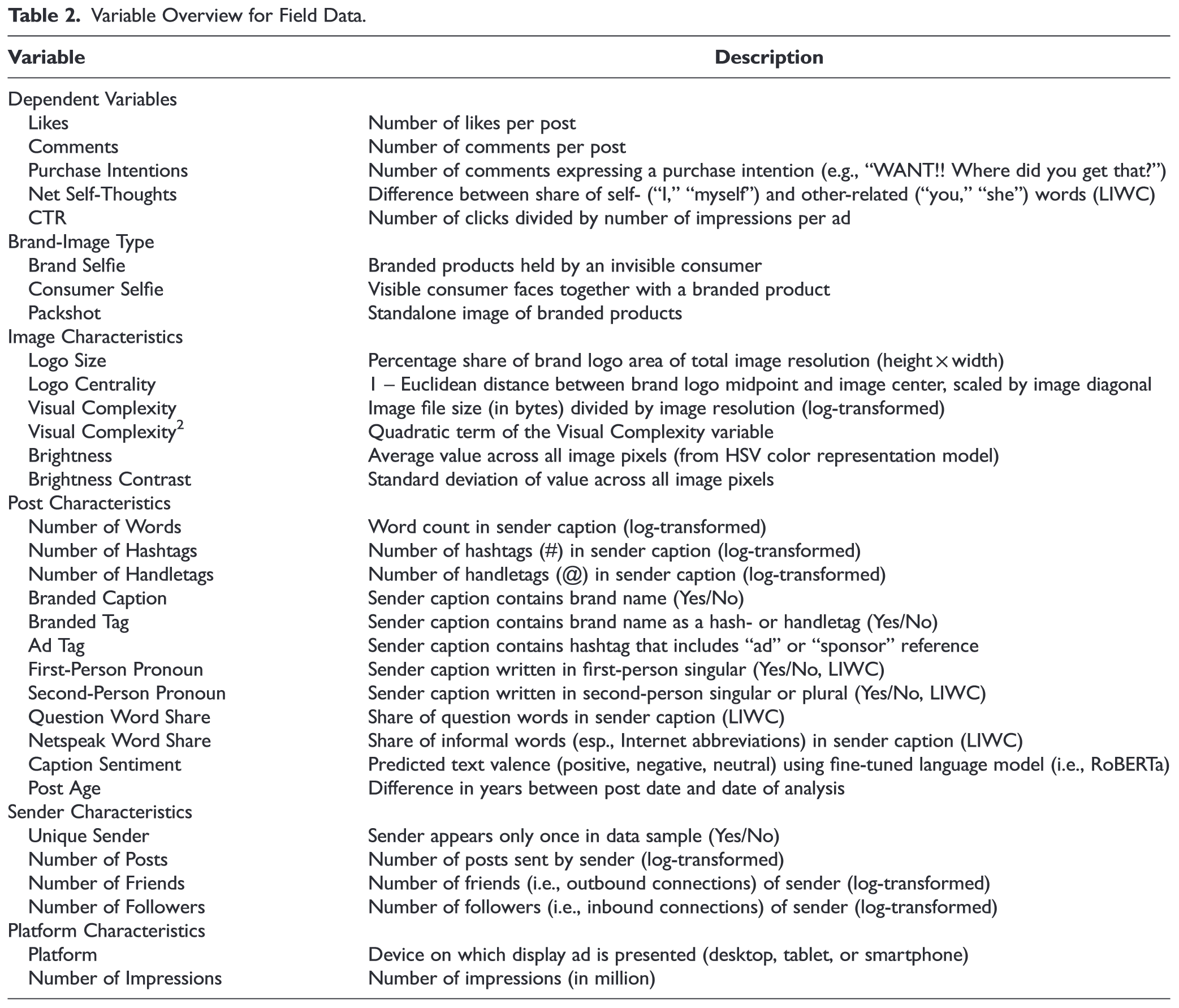
QR : how social media brand images relate to brand engagement
Corpus : Instagram (N = 43,585) and Twitter (N = 214,536)
with 185 visible beverages and food brands