Etudier le concept de transgression dans la littérature en marketing
NLP workshop
26/10/2023
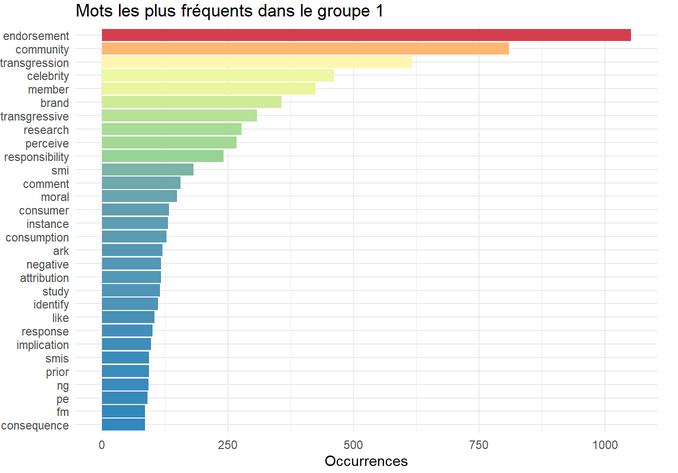
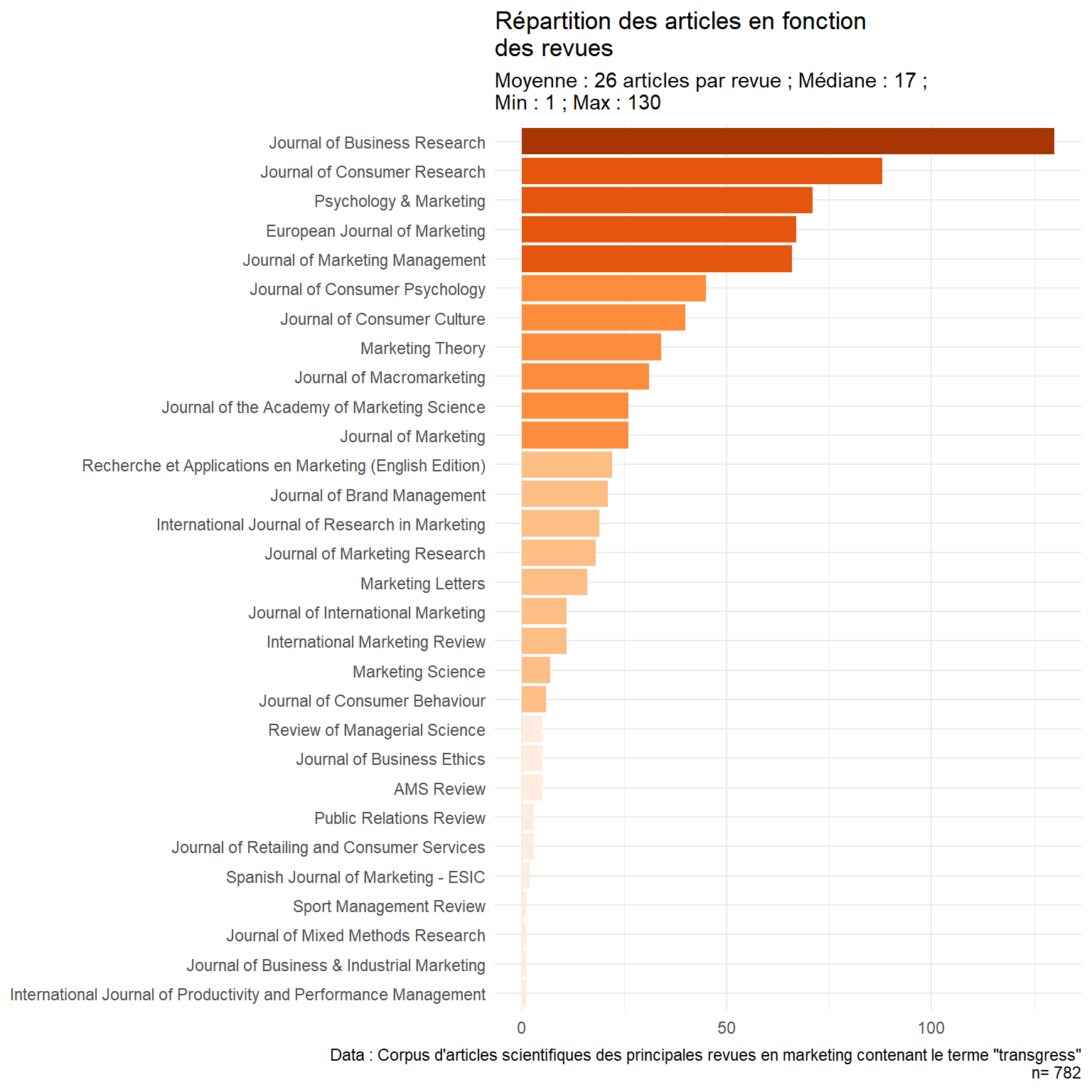
Présentation des données
782 articles issus de 30 revues
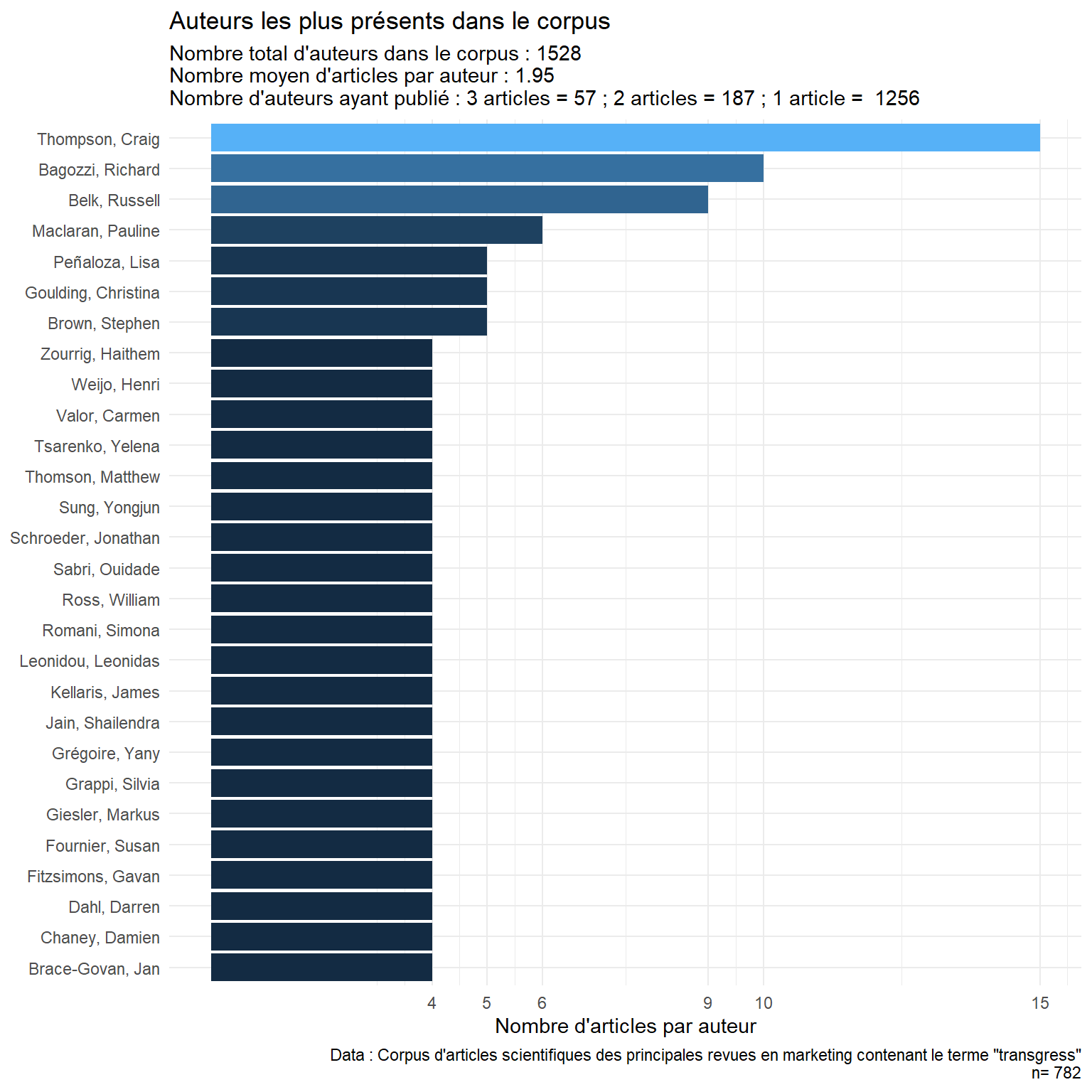
1 528 auteurs, en moyenne 2.48 auteurs par article
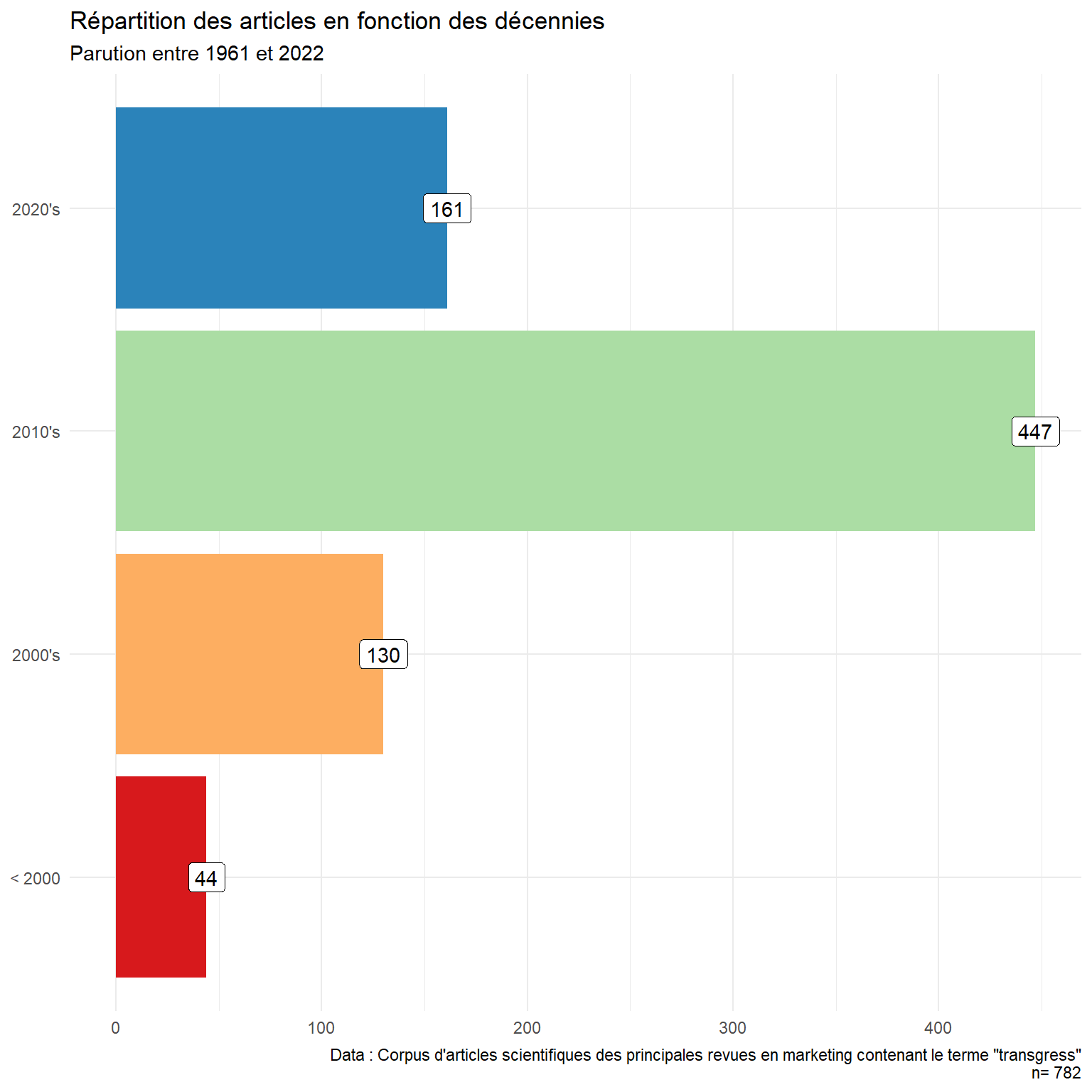
Le corpus s’étend de 1961 à 2022
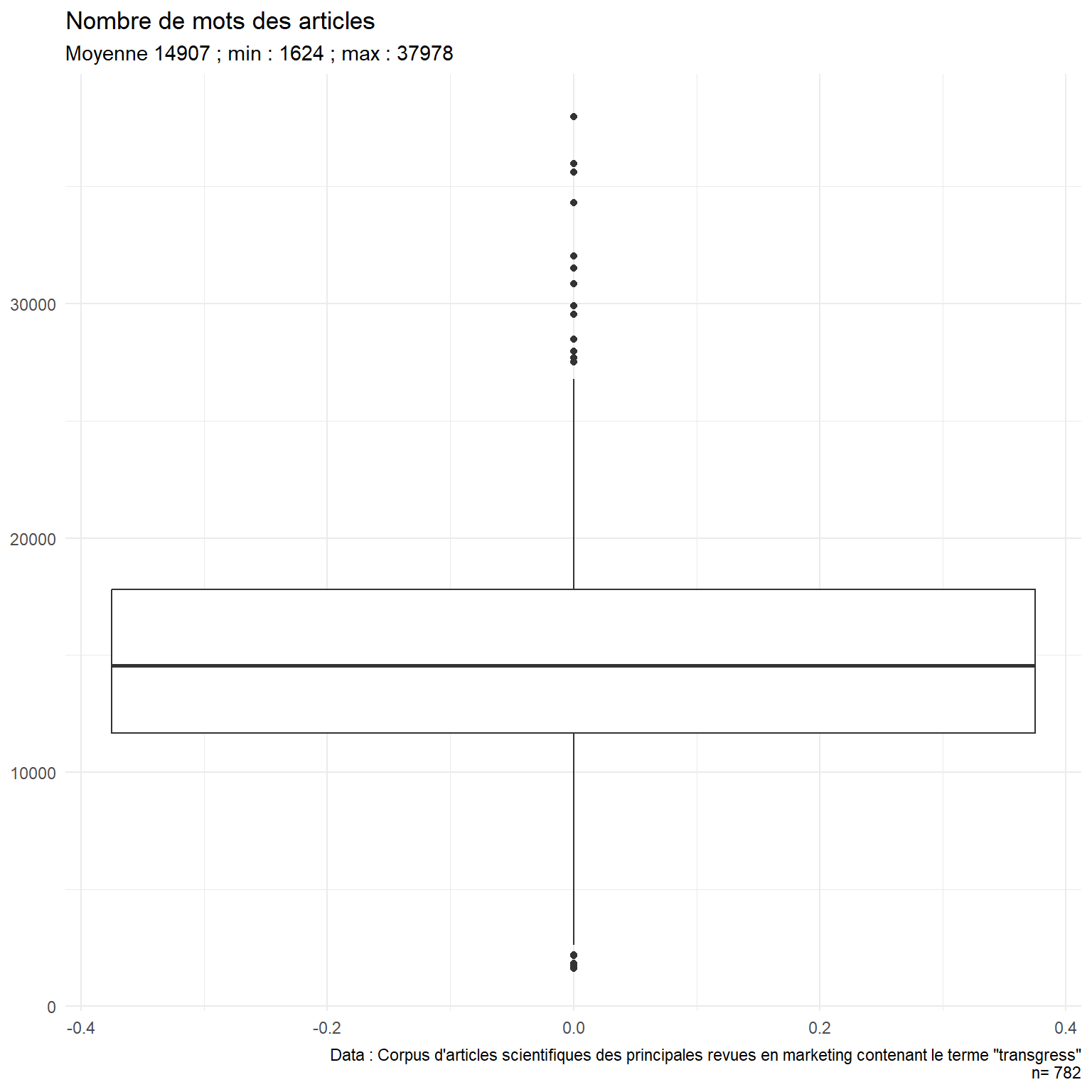
Longueur moyenne d’un article : 14 907 tokens (min : 1 624 ; max : 37 978)
Construction de la base
Les données brutes
![]()
![]()
Préparation des données
Annotation POS
#on initialise l'annotateur
cnlp_init_udpipe()
#on lance l'annotation (très très long pour les 782 documents)
annot<-cnlp_annotate(df2,verbose=100)
#on récupère l'annotation des mots
token<-annot$token
#on sauvegarde le résultat de l'annotation
write_rds(token,"annot_transgress.rds")
#on crée une variable du nombre de caractère de chaque lemme
token<-token%>%mutate(nbcar=nchar(lemma))
#on reconstitue le texte en ne gardant que les adjectifs, les verbes et les noms communs
data2<-token%>%
filter(upos %in% c("ADJ","VERB","NOUN")&nbcar>1)%>%
group_by(doc_id)%>%
summarise(text=paste(lemma , collapse = " "))
#on ajoute ces textes reconstitués à notre tableau fait précédemment
data<-data%>%rename(text_init=text)%>%inner_join(data2)
#on sauvegarde le tout
write_rds(data, "data_transgress.rds")![]()
Préparation des données
Collocations
# On crée le corpus
corpus<-corpus(data, text_field = "text")
# On crée l'objet token
tok<-tokens(corpus)
# On calcule les collocations
colloc<-textstat_collocations(tok,size=c(2,3), min_count = 10)
# On sauvegarde le résultat
write_rds(colloc, "colloc_min10.rds")
# On compose les nouveaux tokens
tok <- tokens_compound(tok, pattern = colloc[colloc$z > 7,])![]()
Préparation des données
KWIC
# On cherche les occurrences contenant "transgress"
kwic_transgress<-kwic(tok, "*transgress*", window = 50)
# On transforme le résultat en data.frame
kwic_transgress<-as.data.frame(kwic_transgress)
# On reconstitue les textes
kwic_transgress<-kwic_transgress%>%
mutate(text_transgress=paste(pre, keyword, post))%>%
select(docname, text_transgress)
# On accole les métadonnées
data_transgress<-data%>%
select(doc_id,journal,year,decade)%>%
right_join(kwic_transgress, by=c("doc_id"="docname"))%>%
rename(docname=doc_id, text=text_transgress)%>%
mutate(doc_id=paste0("text",1:nrow(.)))
# On sauvegarde le tout
write_rds(data_transgress, "data_kwic_transgress.rds")![]()
Classification Reinert
Classification simple

Classification Reinert
Classification double
k=9
res1 <- rainette(dtm, k = k, min_segment_size = 10)
res2 <- rainette(dtm, k = k, min_segment_size = 50)
res <- rainette2(res1, res2, max_k = k)
rainette2_plot(
res, dtm, k = k,
criterion = "chi2",
n_terms = 20,
free_scales = FALSE,
measure = "chi2",
show_negative = FALSE,
text_size = 6
)
## Groups
corpus_rainette$group<-cutree_rainette2(res, k = k, criterion = "chi2")
clusters_by_doc_table(corpus_rainette, clust_var = "group", prop = T)
dfm<-dfm(tok_rainette)
docvars(dfm, "group")<-cutree_rainette2(res, k = k, criterion = "chi2")